

Saturation
Saturation
Every system has its limits. If you keep throwing more and more at a system, at some point it will no longer be able to function properly. The term saturation refers to the state of a system where the demands on the system are high enough that the system is at the limits of its normal performance.
Electrical engineering provides a helpful visualization of saturation. Imagine you want to amplify an electrical signal by a factor of four. This is the behavior you want.
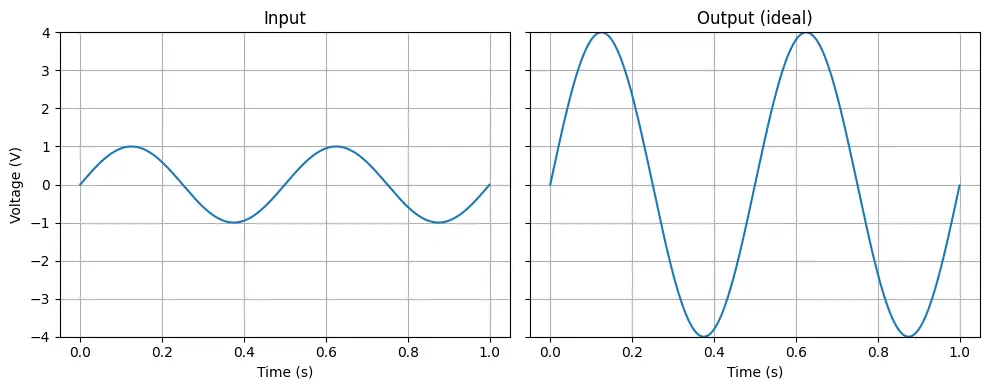
However, real amplifiers have limits on how much the voltage can swing. With some amplifiers, you get a clipping effect, where the output hits some maximum or minimum voltage. In the graph below, this happens above +3.3V and below -3.3V: the signal goes flat instead of following the shape of the input.
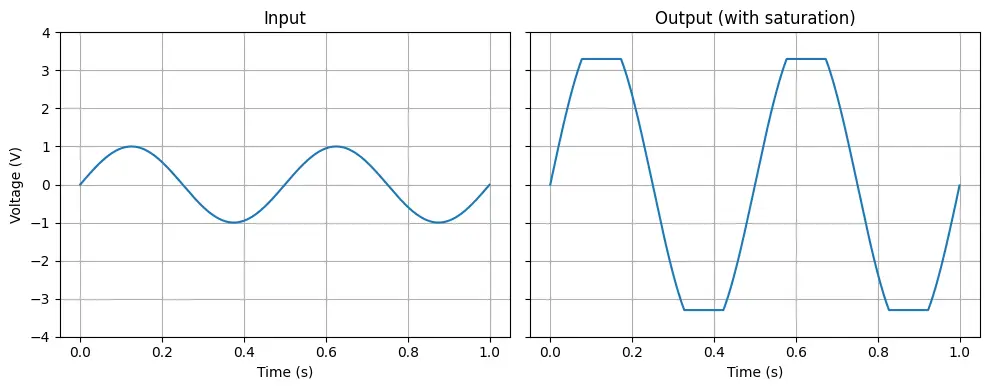
We say that the amplifier is in saturation when this happens. When it is in saturation, it no longer behaves like a linear amplifier anymore. Instead, it has undesired, non-linear behavior.
The Limits of Software Systems
We often think of software as having an ethereal quality to it, “only slightly removed from pure thought-stuff” as Fred Brooks puts it. But software needs to execute on hardware, and hardware always has physical limits. The primary physical limits of hardware are CPU cycles, memory, disk space, and network bandwidth. Each of these is a finite resource with fixed, limited capacity.
Very bad things can happen if you fully deplete these physical resources. For example, if you exhaust the available physical memory on a Linux machine, the dreaded OOM (Out of Memory) Killer will terminate a running process to reclaim some memory, and it may be a process you would prefer to keep running.
Since bad things like OOM kills happen when you reach the physical limits of these resources, there are also virtual limits that engineers put in place to fail before running out of physical resources. For example, many applications use resource pools as a resource management strategy: the two I know best are thread pools and database connection pools. Once all of the resources in a pool are in use, new requests are queued, and the requester must wait for a resource to become free. The effect of queueing is that it increases latency, which changes system behavior.
Speaking of queues, there are queues everywhere in the system, and they frequently have their own virtual limits in the form of maximum sizes. For example, if you wanted to know maximum size of the queue for incoming TCP socket connections on the Linux system, you can see it by doing:
$ sysctl net.core.somaxconn
net.core.somaxconn = 4096
You can view various limits by using the sysctl -a and ulimit -a commands, including maximum number of IP ports, maximum number of threads, or and maximum number of open file descriptors.
Even sysctl and ulimit won’t tell you about all of the limits on your system. I once saw a very confusing “No space left on device” error on a Linux system, even though there was plenty of free disk space. That was the day I learned that there is also a limit on the total number of files and directories that a given filesystem can support, even if these files aren’t consuming all of the space. In my case, the limit had been exhausted by a script that created many small files each time it was executed, but they never got cleaned.
Cloud computing makes it easier for us to provision additional compute, disk, and network resources. We can even automate the process of deploying additional compute resources when we’re running low. Such automated systems are called autoscalers, because they automatically request or return resources based on a signal that indicates load, such as CPU utilization or request rate. But even though we describe the cloud as being elastic (that’s the E in Amazon services like EC2 and EKS), cloud providers themselves have a finite amount of resources. For example, you may get an insufficient capacity error, which means that your cloud provider cannot currently meet your request for additional resources. In practice, autoscalers also have virtual limits, e.g. a configured maximum number of pods or virtual machines that it will scale up to, in order to protect against an expected runaway increase in the number of pods.
Sometimes limits are imposed on us by external systems that we interact with. If your system interacts with a third-party system (such as a cloud provider) over an API, there’s a good chance that they enforce rate limits over those APIs.
System Behavior Changes at the Limit
Virtual limits exist to protect the system from breaching its physical limit. The idea is to reduce the potential damage to the system due to overload by failing earlier in a less harmful way. It’s similar to how a circuit breaker protects your house by opening a circuit to prevent the current from reaching a dangerous level. It’s annoying to have to go to the breaker box and flip the breaker closed again, but it’s better than having your house burn down. However, this may be of little consolation if your application falls over when you’ve breached a virtual limit.
In some cases, the system doesn’t behave any differently until the limit is actually breached. For example, a system that is writing data to disk will behave perfectly normally right until the disk is absolutely full, at which time it will return write errors. Unless you have an alert explicitly set up to track when your disk is almost full, you won’t find out until it’s too late.
In many cases, though, the system behavior starts to change as it nears saturation. As mentioned earlier, a common behavior change near saturation is an increase in response latency. For example, Java applications that run low on available memory will spend more time on garbage collection (gc), including stop-the-world phases of garbage collection which are known as gc pauses. This means that as a service starts to run out of memory, response latency goes up. If the response latency gets too high, this can result in timeout errors. Similarly, high CPU utilization can also increase response latency, because the application threads have to wait to get access to CPU resources in order to service requests.
Examples of Incidents Involving Saturation
Once you start thinking of saturation explicitly as a failure mode, you’ll start to see it in many incidents, either as part of the failure mode itself, or as a factor that makes response or recovery more difficult.
Here are some examples from public incident writeups, my emphasis added.
Waymo
In December 2025, there was a large power outage in San Francisco. This had the surprising effect of paralyzing Waymos in the city. It turned out that Waymos are more likely to issue confirmation checks when encountering an intersection when the traffic lights are out. From the Waymo announcement (emphasis mine):
While we successfully traversed more than 7,000 dark signals on Saturday, the outage created a concentrated spike in these requests. This created a backlog that, in some cases, led to response delays contributing to congestion on already-overwhelmed streets.
Cloudflare
In November 2025, Cloudflare experienced an outage that involved a file being larger than a virtual limit on its size. From the writeup:
The software had a limit on the size of the feature file that was below its doubled size. That caused the software to fail.
Google Cloud Platform
In June 2025, Google Cloud Platform experienced an outage where recovery was made more difficult due to saturation. From the writeup:
Within some of our larger regions, such as us-central-1, as Service Control tasks restarted, it created a herd effect on the underlying infrastructure it depends on (i.e. that Spanner table), overloading the infrastructure.
OpenAI
In December 2024, OpenAI experienced an outage that involved their Kubernetes API servers becoming saturated. From the writeup:
With thousands of nodes performing these operations simultaneously, the Kubernetes API servers became overwhelmed, taking down the Kubernetes control plane in most of our large clusters.
Canva
Also in December 2024, Canva experienced an outage that was triggered by a deploy. There was no problem with the newly deployed code itself, but clients downloading the new javascript files from the CDN set off a series of events that led to their API gateway getting overloaded. From their writeup:
API Gateway tasks begin failing due to memory exhaustion, leading to a full collapse.
Rogers
In July 2022, Rogers experienced an outage that involved routers getting overloaded. From the writeup:
The flood of IP routing data from the distribution routers into the core routers exceeded their capacity to process the information.
Slack
In January 2021, Slack experienced an outage that involved an internal provisioning system getting overloaded. From their writeup:
The spike of load from the simultaneous provisioning of so many instances under suboptimal network conditions meant that provision-service hit two separate resource bottlenecks (the most significant one was the Linux open files limit, but we also exceeded an AWS quota limit).
Resilient Systems Deal Effectively with Saturation
Saturation is a key concern in resilience engineering. In fact, according to the resilience engineering researcher David Woods, the difference between a brittle system and a resilient one comes down to how well a system is able to deal with saturation.
Resilient systems are able to anticipate when saturation might happen soon, and take action before the imminent saturation turns into a real problem. As mentioned earlier, in cases like memory pressure, we can see symptoms that the system is getting close to a limit, but it in other cases like a disk filling up or hitting an autoscaling limit, there won’t be any indications that we’re close to a limit unless we know what signals to look for.
Resilient systems are also able to reconfigure themselves to deal with saturation. Incident response is the paradigmatic example of this sort of system reconfiguration activity, which is why resilience engineering is particularly relevant to incident response. When your organization experiences a saturation-related incident, the human responders need to take action. You can think about the actions that they take as literally changing how the system works, in order to bring the system back to health. That’s what resilience is all about.
 Lorin Hochstein
Lorin Hochstein